-
nva - 简洁高效的前端项目脚手架
奈之若何
nva是什么?
nva是一个基于webpack,提供灵活配置的前端项目脚手架工具,既能支持纯前端项目(html+css+js)的开发需求,也能支持同构JS/SSR项目(node+react/node+vue)的开发,提供了多达8种不同的便捷项目模板,满足自动化开发,数据模拟,资源构建,模块管理,打包发布等等日常开发任务需求
快速开始
安装环境依赖: Node.js (>=4.x, 6.x preferred), npm 3+ and Git
第一步: 安装nva命令行工具
npm install nva -g第二步: 初始化项目
nva init my-project根据命令行提示填写,包含项目模板,框架,是否单页应用,版本号,描述信息,仓库地址,发布协议等等
第三步: 开始开发
cd my-project nva dev -p 3000使用
nva dev启动开发服务器,启动完毕后会打开用户默认浏览器第四步: 测试
nva test根据不同的项目模板执行不同的单元测试
可选: 集成测试
npm i nva-test-e2e -g nva-test-e2e -r path/ro/server.js -c path/to/config.js基于nightwatch的集成测试,测试浏览器为 chrome
后续: 打包发布
nva build完成源码的编译压缩,静态资源合并压缩,路径处理,html注入,构建版本号处理等等
模块化管理
-
增加模块
添加一个空白模块
nva mod my-module以 other-module 为模板添加一个模块
nva mod my-module -t other-module支持批量添加,多个模块名使用英文逗号
,分隔 -
删除模块
删除一个已有的模块
nva mod existed-module -d支持批量删除,多个模块名使用英文逗号
,分隔
项目模板
-
- react + redux 的多页面项目
- react + redux + react-router 的单页面项目
- vue + vuex 的多页面项目
- vue + vuex + vue-router 的单页面项目
-
- react + redux + koa@2 的多页面项目
- react + redux + react-router + koa@2 的单页面项目
- vue + vuex + koa@2 的多页面项目
- vue + vuex + vue-router + koa@2 的单页面项目
配置参数
nva提供尽量简洁高效的方式进行前端项目开发,所以大部分时候使用默认配置即可,但是为了满足不同的业务场景,也提供了灵活的配置入口方便自定义,配置文件都位于项目的 .nva 目录下
.nva 目录结构如下
|-- .nva/ |-- temp/ # 编译缓存目录 |-- mock/ # 模拟数据接口服务配置 |-- user.json # 模拟用户数据接口配置 |-- ... |-- nva.json # 全局配置 |-- module.json # 项目模块设置 |-- vendor.json # 项目第三方包依赖设置-
nva.json全局配置{ "type":"isomorphic", /* 项目类型: `frontend`,`isomorphic`,`react-native` */ "spa":true /* 是否单页面项目(SPA)? */ "jsExt":".jsx", /* 入口 js 文件扩展名 */ "cssExt":".styl", /* 入口 css 文件扩展名 */ "distFolder": "dist", /* 源码编译目标目录名称 */ "bundleFolder": "bundle", /* 项目模块父目录名称 */ "vendorFolder": "vendor", /* 第三方依赖包编译目标目录名称 */ "assetFolder": "asset", /* 静态资源目录名称 */ "fontFolder": "font", /* 字体目录名称 */ "imageFolder": "image", /* 图片目录名称 */ "sourcePath": "src", /* 源码目录名称(仅限纯前端项目) */ "bundleFolder": "bundle", /* 客户端 bundle 目录(仅限同构JS项目) */ "viewFolder": "view", /* html 文件目录名称(仅限同构JS项目) */ "serverFolder": "server", /* 服务端源码目录(仅限同构JS项目) */ "serverEntryJS": "bootstrap.js", /* 服务端入口文件(仅限同构JS项目) */ } -
module.json项目模块配置{ "index": { /* 模块名称 */ "input":{ "js":"index.js", /* 入口 js 文件 */ "css":"index.css", /* 入口 css 文件 */ "html":"index.html" /* 入口 html 文件 */ }, "vendor": {"js": "base","css": "base"} /* 模块依赖引用名称,引用自 `vendor.json` */ } } -
vendor.json第三方依赖包配置{ "js":{ "base":["react","react-dom"] /* 定义一个JS依赖引用 */ }, "css":{ "base":["font-awesome/css/font-awesome.css"] /* 定义一个css依赖引用 */ } } -
mock模拟数据接口服务配置简单的模拟接口配置
module.exports = [{ "url": "/mock/user", /* 接口请求 url */ "method": "get", /* 接口请求方法名称 */ "response": { /* 接口响应 */ "code": 200, "data": { "id": 6, "name": "Mr.smith" } } }]你也可以使用 JSON Schema 一个更具语义化和持续化的模拟数据生成器来生成模拟数据
[{ "url": "/mock/users", "method": "get", "response": { "type": "object", "properties": { "id": { "$ref": "#/definitions/positiveInt" }, "name": { "type": "string", "faker": "name.findName" }, }, "required": ["id", "name"], "definitions": { "positiveInt": { "type": "integer", "minimum": 0, "exclusiveMinimum": true } } } },{ "url": "/mock/user", "method": "post", "response": { "code": 200, "data": { "status": "ok" } } }]
子包
packages 目录下的
nva-corenva-tasknva-servernva-testnva-test-e2e等子包可以独立安装使用nva-core
基础webpack编译配置,满足一般的构建需求
import config from 'nva-core' const buildConfig = config(constants) webpack({ ...buildConfig, entry:'index.js', output:{ ... } }).run((err,stats)=>{ ... })nva-task
nva构建任务集合,可以根据需求自定义组合
var tasks = require('nva-tasks') tasks.frontend.build() //前端项目构建 task.isomorphic.build() //同构JS项目构建nva-server
基于connect的前端开发服务,带模拟数据接口功能
import App from 'nva-server' let app = App() app.listen(3000,()=>{ console.log('==> server stared at %d',3000) })也可以通过命令行方式调用,具体参数说明请参见 nva-task
nva-server -p 5000 -P srcnva-test
基于 karma + mocha 的单元测试服务
运行测试
nva test命令行参数
参数名 默认 描述 -c or —-config 无 测试配置 nva-test-e2e
基于 nightwatch 的e2e测试服务
运行测试
nva test -r path/to/server.js -c path/to/config.js命令行参数
参数名 默认 描述 -c or —-config 无 测试配置 -r or —-runner 无 应用测试服务器 —-browser phantom.js 测试浏览器 代码规范校验
校验项目源码
npm run lint
-
-
updatex,更原生的 Immutable 操作方式
walkon
来由
现在有那么多的 Immutability 库,像 immutable、seamless-immutable、immutability-helper 等,为什么还要造一个轮子呢?理由很感性,用着不怎么爽。要么像 immutable.js 那样,完全改变你的底层数据结构;要么就像 seamless-immutable 那样,你还得记住一堆额外的方法(如
set、setIn等)。而我太懒,只想静静地用原生的方式来操作我的数据。
我们知道最简单的方式就是使用...操作符来浅拷贝对象。像这样:const obj = { a: 1}; const obj2 = {...obj, a: 2}写起来的确很爽,但是当你的对象层级比较深的时候:
const obj = { a: { b: { c: { d: 1 } } } }; const obj2 = {...obj, a: {...obj.a, x: 't', b: { ...obj.a.b, x: 'j'}}} // 或者 const obj2 = {...obj}; obj2.a = {...obj2.a}; obj2.a.x = 't';就要提起精神了。一旦某个变量没控制好,导致直接修改原对象了,那就……都是泪啊。
所以,归纳起来,有两个痛点:- 使用原生数据结构与操作方式,但降低
...带来的繁琐度。 - 确保不会意外地修改原对象。
这就是 updatex 要做的事情。安全、高效地使用原生语法(如赋值
obj.k = v、arr.push()等)来达到 Immutability(不可变性)。示例
import updatex from 'updatex'; const state1 = { a: { b: { c: { d: 1 } } } }; const state2 = updatex(state1, (newState) => { const b = newState.select('a.b'); b.x = 'j';// 这样写没问题,不会影响原先的对象 newState.a.x = 't'; // 这样也是可以的!因为 a 也在 select 的路径里 b.c.d = 2; // 但这样就不行了,会抛异常,因为 c 没有被 select }); console.log(state); // { a: { b: { c: { d: 1 } } } } console.log(state2): // { a: { x: 't', b: { x: 'j', c: { d: 1 } } } }使用 updatex,仅仅只是额外引入两个方法,
updatex()和select()。没有set(k, v)、get(k)、asMutable()、$push等需要额外记忆的方法与表达式,完全可以像操作原生对象与数组一样!API 使用说明
updatex(obj, updater)
传入原对象(
obj)和一个用于数据更新的函数(updater)。原对象将会被冻结,同时浅拷贝出一份新对象(newObj),传给updater。所有的修改应都发生在newObj上。在updater执行完后,如果newObj没有任何修改,则返回原对象;否则返回新对象,同时新对象也会被冻结。updatex(obj, (newObj) => { newObj.x = 1; })select(path)
在
updater里,我们可以直接修改newObj。但是如果要修改它的子对象(如newObj.a.b),就需要预先选择修改范围。这就是select的作用。给它提供一个路径,所有该路径上的节点都会被浅拷贝,这样就可以像往常一样操作对象了。updatex(obj, (newObj) => { newObj.select('a.b'); // 或者 newObj.select(['a', 'b']) newObj.a.x = 1; newObj.a.b.x = 1; })原理
结合前面的来由与示例,updatex 的内部机制已经有一个轮廓了。
- 当调用
updatex(obj, updater)时,通过Object.freeze冻结整个原对象。这样任何对原对象的误操作(修改)都会抛出异常。 - 当调用
select(path)API 时,整个路径(path)内的节点都会通过...来进行浅拷贝。这样你就可以对路径上的任何节点使用原生语法来操作数据了。
特性
- 默认情况下,冻结只会发生在开发环境。在生产环境(
process.env.NODE_ENV=production)会自动停用以提升部分性能(以及避免某些环境不支持Object.freeze)。一个在开发环境上充分测试的代码,停用冻结应该不会导致生产环境上意外修改的情况发生。 - 在
updater返回时,会检查所有select的路径。如果有过度选择(over-select,即选取了但值最终没有发生变化)的话,会有警告。 updater里的所有修改操作可以视作处于批量模式下,而不是修改一次就复制一次对象。自然,也就不需要重新赋值(像obj = obj.set()),不需要return newObj了
- 使用原生数据结构与操作方式,但降低
-
对 virtual-dom 的一些理解
雨鸟
1. 前言
Vue 2.x、React都引入了Virtual Dom的概念,来更加高效地更新dom节点,提升性能。为了能更纯粹地学习Virtual Dom,决定将 Matt-Esch/virtual-dom 作为研究对象。这个项目很纯粹,也很清晰地展示了如何利用虚拟节点来更新视图的整个过程。总体来说,大致分为以下几个阶段。
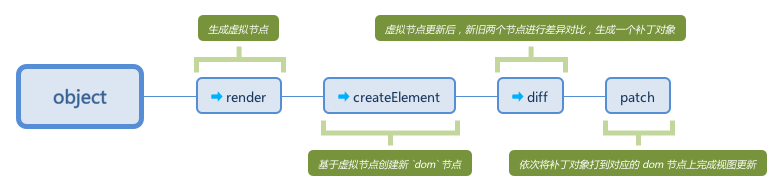
在依次介绍几个过程之前,先来明确几个概念,对后续的学习很有帮助。
2. 基本概念
VNode
VNode虚拟节点,它可以代表一个真实的dom节点。可以通过createElement方法将VNode渲染成dom节点。VText
VText虚拟文本节点,它代表了一个真实的文本节点。内容中若有HTML则会被转义。Hooks
Hooks钩子方法,基于ev-store库给节点注册事件。Thunk
Thunk方法允许开发者参与diff的过程。如对于某节点,能够预先判断,状态不会发生改变,就可以通过这个方法,在diff的过程直接返回旧VNode。Widget
Widget和Thunk的作用有点相似,它参与的是patch的过程。它能定制如何渲染,比如要求某个状态只有为偶数时,重新渲染等。
3. render - 创建虚拟节点
旅程从
virtual-hyperscript/index.js中开始。// @virtual-hyperscript/index.js tag = parseTag(tagName, props);由于
tagName支持#ID,div,.class,div#ID等形式,第一步,进行解析。// @virtual-hyperscript/parse-tag.js var classIdSplit = /([\.#]?[a-zA-Z0-9\u007F-\uFFFF_:-]+)/; var tagParts = split(tag, classIdSplit); var tagName = null; if (notClassId.test(tagParts[1])) { tagName = 'DIV'; }这里比较巧妙,通过匹配
class和id的组合正则对tagName进行分隔,得到一个数组,一次性将标签,类名,id抽离出来。之后分别对其进行预处理。最后一步// @virtual-hyperscript/parse-tag.js return props.namespace ? tagName : tagName.toUpperCase();这里牵扯出一个
namespace的概念,可能在平时多接触HTML对于这个概念比较陌生,但如果了解XML的话,这个概念还是挺重要的,可以用来避免元素名冲突。有兴趣的可以自行了解下,这里不展开介绍。继续往下。// @virtual-hyperscript/index.js transformProperties(props); if (children !== undefined && children !== null) { addChild(children, childNodes, tag, props); }props中并不全是像id,class等可以直接设置到dom元素上的属性值,还支持像ev-click等事件的注册。transformProperties对属性进行预处理。标签名和属性处理完后,开始对子节点进行不同类型的处理,最后组装成childNodes数组。接着就可以生成主角
VNode对象了。// @virtual-hyperscript/index.js return new VNode(tag, props, childNodes, key, namespace);这个
VNode里面都发生了啥?// @vnode/vnode.js // 部分逻辑简化 for (var propName in properties) { if (properties.hasOwnProperty(propName)) { ... var property = properties[propName] if (isVHook(property) && property.unhook) { if (!hooks) { hooks = {} } hooks[propName] = property } ... } } for (var i = 0; i < count; i++) { var child = children[i] if (isVNode(child)) { descendants += child.count || 0 if (...) { hasWidgets = true } if (...) { hasThunks = true } if (...) { descendantHooks = true } } else if (...) { hasThunks = true } else if (...) { hasThunks = true } }这里省略了部分逻辑判断,让逻辑更加清晰。首先,将属性中所有的
Hook注册的事件缓存。然后,遍历所有子节点,统计子孙节点的数量,同时打上各种标记,比如子节点是否有Widget, 是否有Thunk等等。这些标记以及数量统计,现在还看不出什么价值,在后面的几个阶段中,会被用到。不过,按常规来猜测的话,无非是冗余数据,为了后续的一些查找遍历节省时间,提升性能。
4. createElement - 创建
dom节点// @vdom/create-element.js vnode = handleThunk(vnode).a if (isWidget(vnode)) { return vnode.init() } else if (isVText(vnode)) { return doc.createTextNode(vnode.text) }createElement支持传Thunk,为了统一拿到VNode,handleThunk首先做兼容处理。可以理解为handleThunk(vnode, null)。接着,处理掉两个和dom直接相关的两种类型Widget和Text。特殊case处理完了,接着就应该是如何处理VNode了。// @vdom/create-element.js var node = (vnode.namespace === null) ? doc.createElement(vnode.tagName) : doc.createElementNS(vnode.namespace, vnode.tagName) var props = vnode.properties applyProperties(node, props) var children = vnode.children for (var i = 0; i < children.length; i++) { var childNode = createElement(children[i], opts) if (childNode) { node.appendChild(childNode) } }先通过
createElement/createElementNS创建dom元素。接着,applyProperties方法用于将属性props通过setAttribute/removeAttribute/dom[key] = value的方式设置到dom上。当前节点自身生成好后,遍历子元素,递归创建节点,将子节点
appendChild到当前node中。这样,一个真实完整的dom节点就创建好了,可以将它渲染到页面中去了。
5. diff - 比较新旧两个
VNode// @vtree/diff.js function diff(a, b) { var patch = { a: a } walk(a, b, patch, 0) return patch }patch是一个补丁对象,最终的结构如下patch = { 0: {VPatch}, 1: {VPatch}, ... a: VNode };最后
a的value为旧VNode。数字key代表着对应的a的子节点索引,value为相应的补丁。通过
walk方法的递归将一个一个更新补丁打进patch中。为了方便理解,可以这么描述,
walk是用来对比ab两个新旧虚拟节点,如检测到index节点有状态更新,则将VPatch打到patch[index]上。// @vtree/diff.js function walk(a, b, patch, index) { // 全等则直接返回 if (a === b) { return } // 补丁对象 var apply = patch[index] // 当新旧节点类型不同时,标记是否清除旧节点的所有属性以及状态 var applyClear = false // case: 对 Thunk 的处理 // thunks 方法内部将 a , b 转成 VNode ,再调用 diff(a, b) 进行递归 if (isThunk(a) || isThunk(b)) { thunks(a, b, patch, index) } // case: 对新节点为 null 的处理 else if (b == null) { // case: 旧元素不是 Widget // 调用 clearState 方法,该方法干了两件事 // // unhook(): // 通过将该元素以及其子孙元素的所有 hook 属性全都设置为 null 的方式,释放 hook 绑定的方法。 // // destroyWidgets(): // 然后,递归删除该元素中所有 Widget。 // 当然这里的删除,并不是硬删除,而是新建一个 Remove-VPatch。 if (!isWidget(a)) { clearState(a, patch, index) apply = patch[index] } // 删除自身,旧元素,无论是它是 Widget 还是 VNode。 // 所以,源码中有这样一段注释 // "This prevents adding two remove patches for a widget." // 如果旧元素 a 本身是一个 Widget,而上面的条件不判断,会出现有什么情况呢? // 就会发现在 destroyWidgets 中递归时,就已经自身打了个 Remove-VPatch // 如果这里删除自身再次打一个,显然就重复了。 apply = appendPatch(apply, new VPatch(VPatch.REMOVE, a, b)) } // case: 对 VNode 的处理 else if (isVNode(b)) { if (isVNode(a)) { // case: 新旧元素节点相同,只是更新了属性 if (a.tagName === b.tagName && a.namespace === b.namespace && a.key === b.key) { // 对比出更新的属性 var propsPatch = diffProps(a.properties, b.properties) if (propsPatch) { // 打 Props-VPatch apply = appendPatch(apply, new VPatch(VPatch.PROPS, a, propsPatch)) } // 对比子孙元素,递归 apply = diffChildren(a, b, patch, apply, index) } else { // 新旧同为 VNode ,但标签不用,直接新节点更新旧节点 apply = appendPatch(apply, new VPatch(VPatch.VNODE, a, b)) applyClear = true } } else { // 新节点为 VNode ,旧节点不是,直接新节点更新旧节点 apply = appendPatch(apply, new VPatch(VPatch.VNODE, a, b)) applyClear = true } } // case: 对 VText 的处理 else if (isVText(b)) { // 新节点为 VText ,旧节点不是,直接新节点更新旧节点 if (!isVText(a)) { apply = appendPatch(apply, new VPatch(VPatch.VTEXT, a, b)) applyClear = true }else if (a.text !== b.text) { // 同为 VText ,内容不同,直接新节点更新旧节点 apply = appendPatch(apply, new VPatch(VPatch.VTEXT, a, b)) } } // case: 对 Widget 的处理 else if (isWidget(b)) { if (!isWidget(a)) { applyClear = true } // 新节点为 Widget,旧节点无论是否为 Widget,都直接更新 apply = appendPatch(apply, new VPatch(VPatch.WIDGET, a, b)) } if (apply) { patch[index] = apply } if (applyClear) { clearState(a, patch, index) } }walk方法并没有返回值,由于patch是传引用,直接对它进行了修改。这里需要着重说明的是diffChildren方法,它主要用来遍历和递归子节点。// @vtree/diff.js function diffChildren(a, b, patch, apply, index) { var aChildren = a.children // 对新旧节点的子节点进行一个对比,重新排序,生成一个操作补丁对象 // 内容暂且略过,后面会着重来谈。 // { // children: [], // moves: { // removes: removes, // inserts: inserts // } // } var orderedSet = reorder(aChildren, b.children) var bChildren = orderedSet.children var aLen = aChildren.length var bLen = bChildren.length var len = aLen > bLen ? aLen : bLen for (var i = 0; i < len; i++) { var leftNode = aChildren[i] var rightNode = bChildren[i] index += 1 // 旧节点子节点为 null ,新子节点直接插入 if (!leftNode) { if (rightNode) { apply = appendPatch(apply, new VPatch(VPatch.INSERT, null, rightNode)) } } else { // 递归 walk(leftNode, rightNode, patch, index) } // 跳过这个子节点 if (isVNode(leftNode) && leftNode.count) { index += leftNode.count } } // 是否有需要移动的操作 // 只有当有节点有 key 属性时,才会需要移动。 if (orderedSet.moves) { apply = appendPatch(apply, new VPatch( VPatch.ORDER, a, orderedSet.moves )) } return apply }
6. patch - 将
diff对比出的patch更新到相应的dom节点上patch主要关注patchRecursive。// @vdom/patch.js function patchRecursive(rootNode, patches, renderOptions) { var indices = patchIndices(patches) if (indices.length === 0) { return rootNode } var index = domIndex(rootNode, patches.a, indices) var ownerDocument = rootNode.ownerDocument if (!renderOptions.document && ownerDocument !== document) { renderOptions.document = ownerDocument } for (var i = 0; i < indices.length; i++) { var nodeIndex = indices[i] rootNode = applyPatch(rootNode, index[nodeIndex], patches[nodeIndex], renderOptions) } return rootNode }通过前面的讲述知道,
patches对象的数字key为节点索引,value为相应的VPatch, 这里,先通过patchIndices方法将索引取出组成数组indices。接着通过domIndex方法将节点索引和对应的dom节点映射上,生成index对象。在domIndex方法中有个细节需要提一下。// @vdom/dom-index.js indices.sort(ascending)可能大家会想了,
patches对象中不都已经是这样的吗?{ 0: { ... }, 1: { ... }, 2: { ... }, a: { ... } }那么通过
patchIndices中for in遍历patches生成出来的数组不应该本来就是递增的吗?为何还要在domIndex显式进行一次升序排序呢?由于对象是
key-value结构,无序的,无法完全保证在不同浏览器下,通过for in遍历出的顺序一致。这里为了确保表现一致,显式地进行了一次升序排序。接着通过在
applyPatch中,调用patchOp给节点打上相应的patche,也就是对dom进行操作。部分代码如下,结构较简单,这里就不多说了。// @vdom/patch-op.js function applyPatch(vpatch, domNode, renderOptions) { var type = vpatch.type var vNode = vpatch.vNode var patch = vpatch.patch switch (type) { case VPatch.REMOVE: return removeNode(domNode, vNode) case VPatch.INSERT: return insertNode(domNode, patch, renderOptions) ... } }到目前为,已经完成了
virtual-dom从创建到渲染的整个过程。不得不说,文章已经挺长了,但还没有结束。(抱歉,该喝水的,先去喝水吧。码字有些上头了,控制不住记几。)diff阶段中有个当时被一笔带过的reorder方法。这里打算单独谈一谈。在virtual-dom的过程中,这个方法起到了很重要的作用。
7. reorder - 重新排序
reorder会用在哪些场景呢,以Vue的语法,举几个栗子。<!-- 遍历对象 object 是个对象,结构如下 object = { key1: value1 }; --> <!-- case 1 --> <ul> <li v-for="(key, val) in object"> </li> </ul> <!-- case 2 --> <ul> <li v-for="value in object"> : </li> </ul> <!-- items 是个数组,结构如下 items = { { _uid: '...' }... } --> <!-- case 3 --> <ul> <li v-for="item in items"></li> </ul> <!-- case 4 --> <ul> <li v-for="item in items" track-by="_uid"></li> </ul>第一种场景,遍历对象。由于对象是
key-value结构,为无序数据结构。不同环境下的遍历,不能保证其顺序。所以这里内部需要调用reorder强制key按照第一次渲染的顺序进行排序,这样每次状态的更新,都能按照相对固定的顺序进行差异对比,性能最佳.第二种场景,遍历数组。这里又分了两种,区别在于是否用
track-by。问题来了,两种使用有啥区别呢,哪种更好。带着这个问题,我们开始对reorder的探索。方法的最开始,进行了两个特殊逻辑判断。
// @vtree/diff.js ... if (bFree.length === bChildren.length) { return { children: bChildren, moves: null } } ... if (aFree.length === aChildren.length) { return { children: bChildren, moves: null } }其实,我们大多数时候不加
track-by列表循环,在这里就直接return了。这时,是否会有疑惑,这样不就足够了吗,直接返回新的子节点,然后按次序和旧子节点进行对比,对结果也不会有影响。我们来考虑下下面这个栗子。var oldItems = [ { uid: '1', value: 1 }, { uid: '2', value: 2 }, { uid: '3', value: 3 } ]; var newItems = [ { uid: '3', value: 3 }, { uid: '1', value: 1 }, { uid: '2', value: 2 } ];不用
track-by的场景下,在做diff时,会直接按照数组的顺序进行比较,结果是,所有节点都有状态更新,然后最后执行 3 条dom更新操作。这显示是没必要的,因为列表数据并没有发生改变,只是位置改变了。(当然前提是,业务只关心数据,不关心顺序)我们知道, Js 的执行速度是比dom操作快很多的。所以,如果我们预先将newItems进行一个排序,再进行diff,就无需更新dom。那么
reorder是如何重新排序的呢?往下看。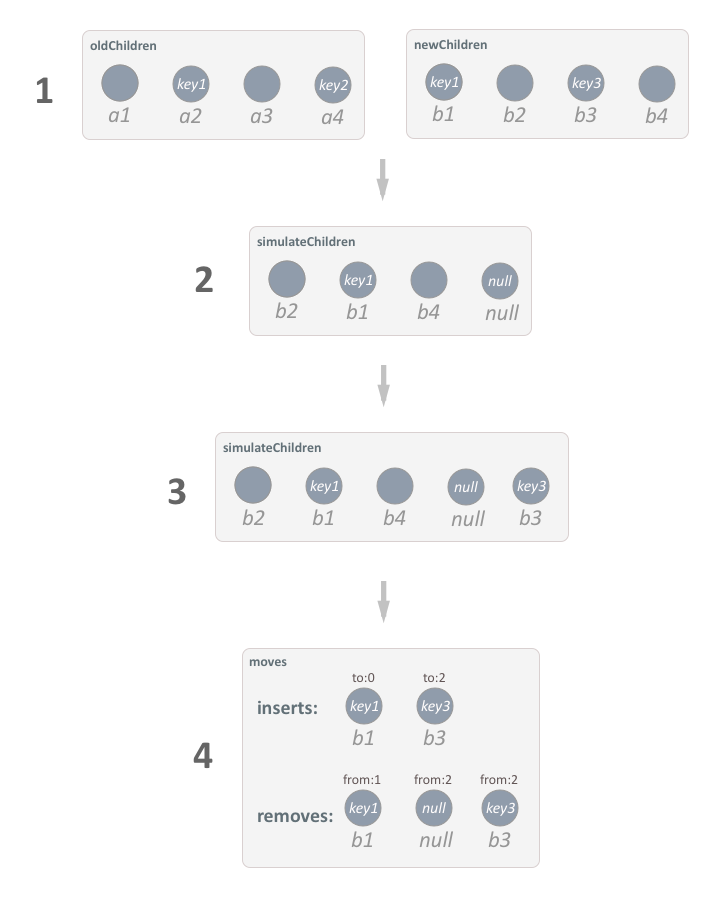
首先要明确一点,在
reorder阶段的排序,并没有真正将newChildren进行重新排序,而只是生成一个insert和remove操作记录数组,将在patch阶段时对dom节点进行操作。这里将
reorder的过程粗略分为四个阶段,分别称之为准备阶段,key 类型顺序还原阶段,新增 key 添加阶段,新旧顺序转换阶段。这里自己定义了一个
key 类型概念。总共有 3 中类型。- 无
key节点: 如{ VText('string') } key节点:如{ h('div', { key: 'key1' }) },{ h('div', { key: 'key2' }) }null节点:标识被删除的元素
1. 准备阶段
newChildren,oldChildren为新旧子节点状态。这里设定的两个新旧子节点还是比较有典型性的。- 有新增
key的节点 - 有删除
key的节点 - 有相同
key的节点 - 有无
key节点
2. 相同
key还原阶段这个阶段的原则是,按照
oldChildren子节点的key类型顺序,将newChildren还原回去。如旧子节点key顺序为[非key, key1, 非key, key2]oldChildren第一个节点为无key节点,对应的newChildren中的第一个无key节点为b2。接着oldChildren第二个节点为key1节点,newChildren中的key1节点为b1。依次类推,得出simulateChildren数组为[b2, b1, b4, null]为啥最后是个
null呢,因为oldChildren中的key2在newChildren中并没有找到。3. 新增
key添加阶段在上面阶段,只是完成了按照旧节点
key类型顺序,将新节点进行了一个还原。但对于新节点中的新key类型节点并没有处理。这个阶段则是将新key类型的节点,插到simulateChildren结尾。[b2, b1, b4, null, b3]4. 新旧顺序转换阶段
这一步算法还是有点绕,建议直接看源码,一步步来观察转换的过程(其实就是我文字太弱,表达不清楚。 = =)。总结起来就是,如何将
simulateChildren的key类型顺序 转换成newChildren的key类型顺序的过程。[非key, key1, 非key, null, key3] ==> [key1, 非key, key3, 非key]最后会生成一个操作队列对象
moves。这里有个问题,为啥将simulateChildren变成newChildren的过程就是oldChildren变成newChildren的过程呢?很显然了,因为通过前两步已经将
simulateChildren的key类型顺序和oldChildren做成一样了。现在回过头看,想刚才的问题?我个人理解为,是否适合用
track-by要看具体的场景。如果子节点状态更新幅度很大,重复数据数据较少,如翻页,就不适合用track-by,省去reorder这一步直接做diff。如果是较少数据会更新,如对于往固定列表中插入一行数据,这时用track-by可以减少dom操作。
8. 后话
到此为止
virtual-dom的大体过程也说的差不多了。(这是真要结束了。)因个人理解深度,文字水平有限。有没说清楚的地方请各位看官多包涵,有说错的地方,请留言指正。谢谢。
^_^
- 无
-
学习Vue.js源码
Fedora
前言
Vue.js 是目前 MVVM 框架中比较流行的一种,在之前的项目中也用过 Vue + Vuex。在使用的过程中,也是一边看文档一边进行开发。对 Vue 的了解也仅限官方文档和一些社区上回答,很大程度上是知其然而不知其所以然。所以在项目告一段落之后,决定从 Vue 的源码入手,学习一下其内部架构。
Vue 源码目录
目标 Vue.js 版本是 2.0.5 /src目录

对应的目录分别为
/compiler、/core、/entries、/platforms、/server、/sfc、/shared- /compiler 目录是编译模版;
- /core 目录是 Vue.js 的核心(也是后面的重点);
- /entries 目录是生产打包的入口;
- /platforms 目录是针对核心模块的 ‘平台’ 模块,platforms 目录下暂时只有 web 目录(在最新的开发目录里面已经有 weex 目录了)。web 目录下有对应的 /compiler、/runtime、/server、/util目录;
- /server 目录是处理服务端渲染;
- /sfc 目录处理单文件 .vue;
- /shared 目录提供全局用到的工具函数。
在刚学习源码时,会对类似
export function observe (value: any): Observer | void { if (!isObject(value)) { return } }这样函数申明或者变量申明感动疑惑的,可以先了解一下 flow。
独立构建&&运行时构建
Vue.js 从 2.0 以后开始出现两个不同的构建版本,详情可以查看官网文档。一开始说到这个,是因为从 Vue 的 build 命令里面可以看到有 7 个 build 版本,这对学习其源码非常有帮助。
const builds = { // Runtime only (CommonJS). Used by bundlers e.g. Webpack & Browserify 'web-runtime-dev': { entry: path.resolve(__dirname, '../src/entries/web-runtime.js'), dest: path.resolve(__dirname, '../dist/vue.common.js'), format: 'cjs', banner }, // runtime-only build for CDN 'web-runtime-cdn-dev': { entry: path.resolve(__dirname, '../src/entries/web-runtime.js'), dest: path.resolve(__dirname, '../dist/vue.runtime.js'), format: 'umd', banner }, // runtime-only production build for CDN 'web-runtime-cdn-prod': { entry: path.resolve(__dirname, '../src/entries/web-runtime.js'), dest: path.resolve(__dirname, '../dist/vue.runtime.min.js'), format: 'umd', env: 'production', banner }, // Runtime+compiler standalone development build. 'web-standalone-dev': { entry: path.resolve(__dirname, '../src/entries/web-runtime-with-compiler.js'), dest: path.resolve(__dirname, '../dist/vue.js'), format: 'umd', env: 'development', banner, alias: { he: './entity-decoder' } }, // Runtime+compiler standalone production build. 'web-standalone-prod': { entry: path.resolve(__dirname, '../src/entries/web-runtime-with-compiler.js'), dest: path.resolve(__dirname, '../dist/vue.min.js'), format: 'umd', env: 'production', banner, alias: { he: './entity-decoder' } }, // Web compiler (CommonJS). 'web-compiler': { entry: path.resolve(__dirname, '../src/entries/web-compiler.js'), dest: path.resolve(__dirname, '../packages/vue-template-compiler/build.js'), format: 'cjs', external: ['he', 'de-indent'] }, // Web server renderer (CommonJS). 'web-server-renderer': { entry: path.resolve(__dirname, '../src/entries/web-server-renderer.js'), dest: path.resolve(__dirname, '../packages/vue-server-renderer/build.js'), format: 'cjs', external: ['stream', 'module', 'vm', 'he', 'de-indent'] } }这里,关注的重点是 runtime 的版本。
Vue.js 结构
通过上面的分析,可以看到 Vue.js 的组成是由 core + 对应的 ‘平台’ 补充代码构成(独立构建和运行时构建只是 platforms 下 web 平台的两种选择)。

core 目录下面对应的
components、global-api、instance、observer、util、vdom模块。Vue.js 的目标是通过尽可能简单的 API 实现响应的数据绑定和组合的视图组件
Vue2.0 在保持实现‘响应的数据绑定’的同时又引入了 ‘virtual-dom’,那么它是怎么实现的呢?
响应的数据绑定
Vue.js 实现数据绑定的关键是 Object.defineProperty(obj, prop, descriptor),这也是为什么 2.0 不支持IE8原因之一,IE8 下无法实现 defineProperty 的腻子脚本。当然实现类似功能的现代语法还有 Object.observe (已经废弃)和 Proxy。
Vue 源码对此实现的逻辑在core/observer目录下。 关注三个类 class Observer,class Dep,class Watcher
class Observer 在 core/observer/index.js 中export class Observer { value: any; dep: Dep; vmCount: number; // number of vms that has this object as root $data constructor (value: any) { this.value = value this.dep = new Dep() this.vmCount = 0 def(value, '__ob__', this) if (Array.isArray(value)) { const augment = hasProto ? protoAugment : copyAugment augment(value, arrayMethods, arrayKeys) this.observeArray(value) } else { this.walk(value) } } walk (obj: Object) { const keys = Object.keys(obj) for (let i = 0; i < keys.length; i++) { defineReactive(obj, keys[i], obj[keys[i]]) } } observeArray (items: Array<any>) { for (let i = 0, l = items.length; i < l; i++) { observe(items[i]) } } }Observer 类实例是用来附加到每个被观察的对象(后面称之为响应式对象)上的。普通对象通常是不会变成‘响应式对象’的。经过defineReactive函数的调用,才会将传入的普通对象变成‘响应式对象’。而 defineReactive 就是利用了 Object.defineProperty 这个方法。 defineReactive 源码如下:
export function defineReactive ( obj: Object, key: string, val: any, customSetter?: Function ) { const dep = new Dep() const property = Object.getOwnPropertyDescriptor(obj, key) if (property && property.configurable === false) { return } const getter = property && property.get const setter = property && property.set let childOb = observe(val) Object.defineProperty(obj, key, { enumerable: true, configurable: true, get: function reactiveGetter () { const value = getter ? getter.call(obj) : val if (Dep.target) { dep.depend() if (childOb) { childOb.dep.depend() } if (Array.isArray(value)) { dependArray(value) } } return value }, set: function reactiveSetter (newVal) { const value = getter ? getter.call(obj) : val if (newVal === value) { return } if (process.env.NODE_ENV !== 'production' && customSetter) { customSetter() } if (setter) { setter.call(obj, newVal) } else { val = newVal } childOb = observe(newVal) dep.notify() } }) }Object.defineProperty(obj, prop, descriptor) 中的第三个参数就是对象描述符。对象描述符的传入是有要求的,分为赋值描述符合存取描述符。而每次传入的参数只能是其中之一,很显然在 defineReactive 中传入的就是存取描述符,在传入的存取描述符对象中有get,set方法。set 方法会实例化一个 Observer ,get方法会关联到一个 class Dep 的实例。但是仔细看get方法,发现只有在 Dep.target 值为 true 的时候才会发生关联。所以,接下来分析一下 class Dep 的源码。
export default class Dep { static target: ?Watcher; id: number; subs: Array<Watcher>; constructor () { this.id = uid++ this.subs = [] } addSub (sub: Watcher) { this.subs.push(sub) } removeSub (sub: Watcher) { remove(this.subs, sub) } depend () { if (Dep.target) { Dep.target.addDep(this) } } notify () { const subs = this.subs.slice() for (let i = 0, l = subs.length; i < l; i++) { subs[i].update() } } } Dep.target = null const targetStack = [] export function pushTarget (_target: Watcher) { if (Dep.target) targetStack.push(Dep.target) Dep.target = _target } export function popTarget () { Dep.target = targetStack.pop() }class Dep 就是连接 class Observer 和 class Watch 类的介质。因为在set方法里面最终会调用
dep.notify()方法。class Dep 类中的 notify 方法会使这个dep实例下所有的 watch 数组更新一次。class Watch 类的 update 方法会调用对应的回调方法,进行对应的更新。同时在前面提到的get方法关联class Dep实例时,是在 Dep.target 为true的时候才会执行。通过源码可以看到Dep.target的初始值是null,也就是默认是不会执行关联的。源码上对此做了注释,可以看到 Dep.target 是被赋予全局性质,用来保证同一时刻只有一个Watcher实例在被‘关联’(源码注释的地方是’evaluated’)。而激活 Dep.target 这个属性的是函数pushTarget 。pushTarget 函数就在 class Watcher 中调用了。class Watcher 的源码如下:export default class Watcher { vm: Component; expression: string; cb: Function; id: number; deep: boolean; user: boolean; lazy: boolean; sync: boolean; dirty: boolean; active: boolean; deps: Array<Dep>; newDeps: Array<Dep>; depIds: Set; newDepIds: Set; getter: Function; value: any; constructor ( vm: Component, expOrFn: string | Function, cb: Function, options?: Object = {} ) { this.vm = vm vm._watchers.push(this) // options this.deep = !!options.deep this.user = !!options.user this.lazy = !!options.lazy this.sync = !!options.sync this.expression = expOrFn.toString() this.cb = cb this.id = ++uid // uid for batching this.active = true this.dirty = this.lazy // for lazy watchers this.deps = [] this.newDeps = [] this.depIds = new Set() this.newDepIds = new Set() if (typeof expOrFn === 'function') { this.getter = expOrFn } else { this.getter = parsePath(expOrFn) if (!this.getter) { this.getter = function () {} process.env.NODE_ENV !== 'production' && warn( `Failed watching path: "${expOrFn}" ` + 'Watcher only accepts simple dot-delimited paths. ' + 'For full control, use a function instead.', vm ) } } this.value = this.lazy ? undefined : this.get() } get () { pushTarget(this) const value = this.getter.call(this.vm, this.vm) if (this.deep) { traverse(value) } popTarget() this.cleanupDeps() return value } }到这里,class Observer、class Dep 和 class Watch 三个类的关系就清楚了。这也是 Vue 中实现数据绑定用到的观察者模式的体现。
Virtual-dom
React 的大热,是因为其带来了 ‘Virtual-dom’ 和数据驱动视图的理念(尽管很多人觉得后者更重要)。这里并不想比较 ‘Virtual-dom’ 和原生的 DOM 操作谁快谁慢的问题(事实上在 dom 结构改动很多的情况下,原生 DOM 操作比较快。。。),仅仅是理解一下
Virtual-dom。
‘Virtual-dom’是一系列的模块集合,用来提供声明式的DOM渲染。来看一个简单的 DOM 片段<div id="parent"> <span class="child">item1</span> <span class="child">item2</span> <span class="child">item3</span> </div>对 DOM 片段结构抽象一下:一个根节点 div ,三个元素子节点 span (对应的内部文本节点)。然后用 JavaScript 对象表示:
const dom = { tagName: 'div', props: { id: 'parent' }, children: [ {tagName: 'span', props: {class: 'child'}, children: ["item1"]}, {tagName: 'span', props: {class: 'child'}, children: ["item2"]}, {tagName: 'span', props: {class: 'child'}, children: ["item3"]}, ] }进而扩展到整个 HTML 页面的结构。整个 HTML 页面结构其实可以用一个 JavaScript 对象表示,通过这个抽象,对
dom对象的修改就会影响到HTML页面的结构。所以在改变HTML结构的时候,我们仅仅是修改 JavaScript 对象。相对以前修改HTML页面结构式通过直接修改 DOM 元素,现在变成修改对应的 JavaScript 对象。Vue.js 在对 DOM 的抽象做的更细致,具体代码可以看core/vdom/create-element.js。在实现了对 HTML 结构的映射后,接下来就是 ‘Virtual-dom’ 的重点,如何比较两个不同HTML结构树的对象–
diff算法。diff算法比较的就是两颗’树’的差异。而传统的’树’比较是一个时间复杂度为O(n^3),这个效率明显是不够的。而 HTML 的结构树的改变不同于传统的’树’。HTML 结构树的改变,很少会出现跨越不同层级的改变。基于这个实际上的差异化改变,‘Virtual-dom’的diff算法的时间复杂度是O(n)。有兴趣研究diff算法的,可以看下这里。在解决了
diff算法核心问题后,就要把’新 HTML结构树’相对’老HTML结构树’的差异应用到’老HTML结构树’上–‘patch’。Vue.js 在 ‘patch’ 的解决方案上参考了开源项目 Snabbdom。源码篇幅有点长,也有些复杂,想深入了解的可以配合开源的项目一起分析。至此,‘Virtual-dom’ 大致的实现逻辑也清楚了。Vue.js 的源码在架构组织上还有很多可以学习的,比如区分’核心模块’和’平台模块’。另外内部实现的 ‘keep-alive’ 组件也是值得关注的地方,更多了解请到这里。以上只是很’粗浅’的学习,不对的地方希望大家指出来(认真脸.jpg)。
参考资料
Vue官网文档
What is Virtual Dom
The difference between Virtual DOM and DOM
-
在ubuntu中安装mongodb六部曲
兰悦儿格格
话说,楼主以前是吃过苦的,之前我因为想学 MongoDB ,所以用我的 windows 来安装 MongoDB ,结果苦了我了,一整天都没装好。
后来看到同事用自己的 linux 系列服务器一下子就装好了,我。。。
所以奉劝大家,要么在 windows 上直接下载 MongoDB 软件比如 mongoChef Core ,要么,就还是用 linux 系列比如 ubuntu 来装吧。 安装某些软件,windows用户伤不起啊。
1. 根据包管理系统来导入公钥
这里的包管理系统指的就是你的包管理工具是dpkg 还是 apt ,或者是其他的包管理工具.
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv EA312927这个公钥呢,就是酱紫
—–BEGIN PGP PUBLIC KEY BLOCK—– Version: GnuPG v1.4.11 (GNU/Linux)
mQINBFYYLZUBEADTvHI/DDlJY4JCLh7chtQiKkj8kFpqOtY4x6luOQWvYNXfvso1 yoKqKnU33Fh3JY4dWClXzv40PcVH4pIi95enzCLGvU30GNDsfmueV9vkq5HrCMMZ rQ1M9/4HgrnbRvLhvcb4VY+RELEdcHWhUkYTpG00YuEHdgJ3PoPL5pDu1L1z/MwE TVwCr63kl2HhgzqtpaXC00hbLSN/+GD3guCrIJy8Gfz6yfgpmCxr5KyOG2fdRoZL mRKNzMdSua+bLeTM8BXqJpSB8BBsBSbnNuCLZdZhhSm4P7SUSrPoSRRzEMDwzv6e 1JqJqVaiApBoSX+elUzoYrglSkaPqWiT6kzlWw7ZOTTqKkojQftYGOvDYdvSKq0z e8QzA/22FmDKzurBpv7Tus9VV+yMlxTCVGtb74u8j6pRO2jxs9w6Ur2CfQJgddtN wbiIKWI1F7//YDSJncJRfW19cnOyrOqiNoPQqsF+YFexEy4wSs94eQ3EfBzbYjSt EtJVSV5HCjJtIZjOxRJnyN8ZZZCPwhizvU+zGcCiAi0bwcur9kti+bnIbYCTURFy WCLHM09HNCYg5ZBCa+6+ZDiOs+Y3sjs+Dzrrt3eAh+ny53BSBS+MlZ2CtvJZdjMu JBAN2haiMYtaVIgmnfzfPZDJ1mZag/lGy++lufSQNJDPfVqVRlj17SG6kwARAQAB tDdNb25nb0RCIDMuMiBSZWxlYXNlIFNpZ25pbmcgS2V5IDxwYWNrYWdpbmdAbW9u Z29kYi5jb20+iQI+BBMBAgAoBQJWGC2VAhsDBQkDwmcABgsJCAcDAgYVCAIJCgsE FgIDAQIeAQIXgAAKCRDWj6UP6jEpJ8KPD/9ZMK86x0ZNPK6PrJ4mmc7TVYzl9/Fb PThLIvX/f1pUcUiLha0+TC7pYw8vWtl2iiOfAWI2bzPcQ6qrxo2wEvEE27ApL9PU hbaUA0C/3BQzVwCojKka8If1GIf8dJVpxeai7Mcsx2vf+0svvoMvFOrTK5G2AnyH MAY0Ko4Mw/1D/gFO1DjO90S8H6yvA0hapjwYQ8Tul0/u4wBjTRd3SNaoNnx9zcqD evAmrDjNHDAr3WXhDlYCnciHQoqI+XUgnFMA+3zY0YczSGAU1aeUUj9F6Wr5fOlN 4pvzIaI+dQL/K9lY/2GgXEATRTuHYFZxT7gl7V6Su9wNVEBqTRkpnoGpxh1OQuRv SHIRD9GAcP9eTD4AknvfEDbe/Hvqf9gDErGNEjy31hxSjZ5gl7WOJZw0rftlw0GN pPmKiuT54kwUrluxtAXey9JaQ2ifomZByrxczWpIXSAi8G4ljiyJVkohmotbEiXh PAYNtxWf0y57EQ6DO1d8yGv4BiB08YtrqaH/cFpNtRTgvajJm5iW55yb4v1Inf4d 9f7j9cQmFufJMtOMiF8/yDiFeOBkSfJXjx3+of4pXLIAuMbX95RWuAa7FOvL7xrs RDhdohAjLyyBRcJBv8yQ9BYXOekWGIiTbhUW9L1ySkpdQ8+2QOKxOgK4Yl0psMPn YXy2T09NgATr0A== =8Qhy —–END PGP PUBLIC KEY BLOCK—–
2. 创建 MongoDB 的一个列表文件(注意,这里系统不同,安装代码也不同)
如果你的 ubuntu 系统是 16.04 ,执行下面这个就好
echo "deb http://repo.mongodb.org/apt/ubuntu xenial/mongodb-org/3.2 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-3.2.list但是如果你的系统是 14.04 系列的,那就得执行这个了
echo "deb http://repo.mongodb.org/apt/ubuntu trusty/mongodb-org/3.2 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-3.2.list想了想,还是把 12 的也附上吧
echo "deb http://repo.mongodb.org/apt/ubuntu precise/mongodb-org/3.2 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-3.2.list3. 更新本地安装包的数据源
sudo apt-get update4. 安装 MongoDB 包
sudo apt-get install -y mongodb-org这里说一句,如果你看官网的话你会发现有好几个包,那么我为什么会让大家只是安装 这个包呢。
官方对 mongodb-org 这个包的定义
A metapackage that will automatically install the four component packages listed below. 这里就说了。它跟着就会自动安装其他四个包,所以你只要选择,安装这一个包就够了 另外, /etc/mongod.conf 配置文件会默认把你 这个包的 bind_ip 设置成 127.0.0.1
5. 创建一个系统服务文件
在 /lib/systemed/system 创建一个 mongod.service 文件,文件内容如下
[Unit] Description=High-performance, schema-free document-oriented database After=network.target Documentation=https://docs.mongodb.org/manual [Service] User=mongodb Group=mongodb ExecStart=/usr/bin/mongod --quiet --config /etc/mongod.conf [Install] WantedBy=multi-user.target6.运行 MongoDB
开始运行
sudo servercie mongod start验证 Mongodb 是否开启成功
在/var/log/mongodb/mongod.log查看是否有这么一句话
[initandlisten] waiting for connections on port <port>果然在mongod.log的最新的日志信息里找到了这么一句话
2016-11-21T05:53:34.772-0500 I NETWORK [initandlisten] waiting for connections on port 27017停止 MongoDB
sudo service mongod stop重启
sudo service mongod restartok。那怎么校验你是否安装成功,MongoDB 已经能用了呢? 在你的命令行里输入
mongo这个时候当你看到类似这样的输出之后就代表已经 ok 了
MongoDB shell version: 3.2.9 connecting to: test Server has startup warnings: 2016-11-21T05:53:34.769-0500 I CONTROL [initandlisten] 2016-11-21T05:53:34.769-0500 I CONTROL [initandlisten] ** WARNING: You are running in OpenVZ which can cause issues on versions of RHEL older than RHEL6. 2016-11-21T05:53:34.769-0500 I CONTROL [initandlisten]
-
一步一步教你怎么在本地用 Babel6
兰悦儿格格
之所以要学习 Babel6 是因为想要在项目里用上 ES6 ,所以就折腾了下。
一开始,学习 ES6 是直接在浏览器运行的,结果发现我升级到最新的 Chrome 浏览器之后,它对 ES6 的支持只有65%, 所以,发现还是得学 Babel 。
后来觉得老是转太麻烦,而且通过网页去转也太 low 了吧。我们既然要在项目里用 ES6 ,那肯定还是得在本地集成这个转换。先来看官方定义 Babel 是什么 Babel 是一个通用的多用途 JavaScript 编译器。通过 Babel 你可以使用(并创建)下一代的 JavaScript,以及下一代的 JavaScript 工具。在看怎么安装考虑之后,我决定直接用 Babel6 。那么就跟着我一步步走上 Babel 之旅吧
1.新建一个文件夹,这里我取名叫 es6
mkdir es62.进入这个文件夹
cd es63.初始化一个npm的项目.
npm init4.安装babel的核心模块
npm install -g babel-cli注意,本来这里我打算直接用 cnpm 安装的,结果报错,就还是直接用 npm 安装了。好, Babel 就装完了。不过你不要以为到这里就完了,要想达成在本地编译 Babel ,还有一些其他的事情也是要做的。我们有一个叫做 test.js 的文件,它里面的内容是
"use strict"; let userName = "吴晓兰"; console.log(userName);眼下,我们可以试试先来编译我们的 Babel 文件。
babel test.js这样就会把 test.js 的编译结果直接输出终端。如果你用
babel test.js -o testR.js就能看到刚才的命令直接把 test.js 这个文件拷贝成一个新文件,叫做 testR.js 了。 但是我们打开 testR.js 一看,会觉得不对呀,这里面的内容怎么和 test.js 里的内容是一样的,我们是要编译文件,而不是拷贝文件呀。 别着急,每次直接在命令行里执行
babel命令也太麻烦了,我们直接把我们的构建写到npm scripts里去吧。 看一下因为在本地执行npm init而生成 package.json 文件的内容{ "name": "es61", "version": "1.0.0", "description": "", "main": "index.js", "scripts": { "test": "echo \"Error: no test specified\" && exit 1" }, "author": "", "license": "ISC" }找到里面的 scripts ,可以看到已经有一个叫做 test 的任务 demo ,我们给 scripts 加一个属性,build 加了之后就变成这样了。
{ "name": "es61", "version": "1.0.0", "description": "", "main": "index.js", "scripts": { "test": "echo \"Error: no test specified\" && exit 1", "build": "babel test.js -o testR.js" }, "author": "", "license": "ISC" }然后执行。
npm run buildok,这下终于把构建任务写在 npm scripts 里了。但是我们的终极任务还是想在编程的时候直接转换 es6 的代码嘛,对不对,别着急,这就来了。由于 Babel 是一个可以用各种花样去使用的通用编译器,因此默认情况下它反而什么都不做。你必须明确地告诉 Babel 应该要做什么。 那么我们怎么明确告诉 Babel 我们是要干什么呢?在项目里建一个 .babelrc 文件,在文件里写上
{ "presets": [ "es2015" ], "plugins": [] }然后再执行
npm install babel-preset-es2015 --saveok,我们现在再执行
npm init build会发现 restR.js 的文件已经变成了。"use strict"; var userName = "吴晓兰"; console.log(userName);这正是我们想要的结果。但是你以为这就完了么?不,这样是会有隐患的。请注意 Babel 的作用是把 es6 的语法编译成 es5。但是比如如果你直接用了一些新的 API ,它却可能会出错了,因为有一些 API ,它并不会编译。
为了解决这个问题,我们可以使用一种叫做 Polyfill 的技术,简单的说, Polyfill 是在当前运行环境里用来复制或者说模拟尚不存在的原生 API 的代码。那么,你可以安装这个插件。
npm install --save babel-polyfill好啦,就这样吧。哈哈哈,其实最后一步,也就是安装 Polyfill 对于我们 wecash 闪银来说,是可以不用的,因为我们 IE 都不用兼容,所以基本上不会有这个问题。
-
开摊大吉!
雨鸟
臭豆腐前端 - STFFE
「Stinky Tofu Front-End ~ 前端是工作,臭豆腐是生活,对于我们,缺一不可。我们在星城,倾听世界 。」